

At Traba, our mission is to make the industrial supply chain operate at peak efficiency.
The global supply chain impacts nearly every person on the planet: it produces the steel and concrete in the buildings we live and work in, processes the food on our tables, and powers the 3PL networks that deliver essentials overnight.
Yet for too long, it has been held back by labor inefficiencies that slow things down and compromise quality. Solving the key blockers in this pipeline therefore has positive downstream effects for all humankind.
The Problem
Arguably the biggest problem in modern supply chains (and the core of our product) is staffing–the employment of the teams necessary to execute the processes within the industrial supply chain, often inside warehouses and fulfillment centers.
Specifically, the challenge is to consistently find and employ reliable temp staffing: due to the nature of supply chains fluctuating throughout the year, businesses need a dynamic, temporary workforce to match their specific demand curves.
The good news is, there is no shortage of people up to the task. There are over 4 million American temps in the industrial supply chain at any given time, and millions more who are looking to enter or reenter the field.
But the industrial supply chain is not a field that anyone can simply walk into. They generally have strict processes for evaluating the specific technical and nontechnical skills, motivations, certifications, and and required to perform a given job.
To fix industrial staffing, we must qualify these workers at volume — fast, accurately, and with ideally minimal to zero human effort.
We knew we had to build an AI Interviewer.
Why ElevenLabs?

By late 2024, high-quality, low-latency TTS/ASR stacks became viable for real time telephone conversations. We knew that we wanted a strong partner we could grow with: an expert at real time communications that could stay on the innovative peak of generative voice AI.
ElevenLabs provided the middle ground we needed. They offered:
High-quality voices: natural, multilingual voices that made conversations feel human rather than robotic.
Low latency: fast enough for real-time interactions without awkward delays.
Flexibility and control: the ability to orchestrate multiple agents, experiment with prompting strategies, and integrate directly into our systems.
Reduced complexity: handling grimy parts of the audio pipeline so we could focus on their unique workflows.
We pushed for those capabilities; they shipped, and we integrated them efficiently into our telephony stack.
Check out ElevenLabs' blogpost on Scout here.
Key Requirements
The key goals for our AI recruiter were that it must:
run thousands of interviews in parallel
be able to communicate with workers multimodally, both SMS and VOIP
qualify based on a gamut of common questions that pertain to every job, as well as custom questions specific to a particular role, facility, region, or combination of multiple factors.
respect eligibility and compliance constraints of the job as well as the worker
challenge the interviewee and go further in depth where necessary
hand back structured, decision-grade evaluations to the rest of the system
give sufficient exposition to the worker about the job they showed interested in
adhere to responsible AI principles and avoid bias (see our AI Policy)
But to put very simply, the goal was simple. Give workers and businesses:
The flexibility, depth, and personalization of a human led recruiting process
The speed, consistency, and scalability of an automated one.
Simple Beginnings: Scout V1
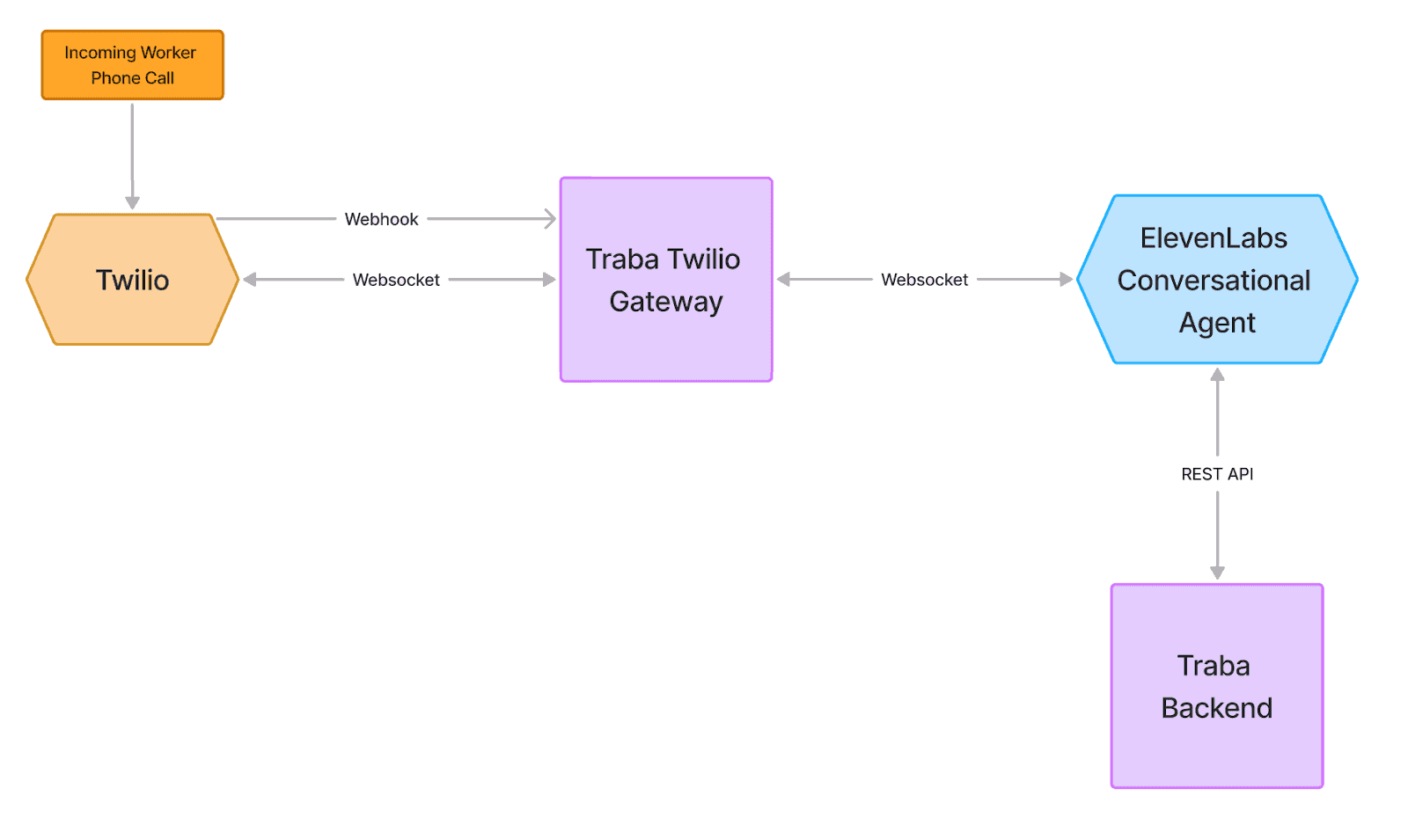
For our MVP release, the goal was to prove that an AI recruiter could hold a structured phone interview end-to-end that would give us a strong signal on a worker’s fit for a given role.
We kept the design simple so that we could start testing and providing leverage to our operations team as quickly as possible.
Single Agent Architecture. The initial version of Scout used a single LLM agent with a large context prompt that had role-specific content injected. This agent was responsible for all interview functions: introductions, providing logistics, assessing candidate aptitude and handling any follow ups.
Fixed Question Bank. Questions for each interview consisted of static questions about the logistics for the shift as well as questions based on a fixed set of attributes that could be vetted. For example, a role could specify that it needs the candidate to be able to operate a forklift, and a pre-defined set of questions about driving forklifts would be injected to ask.
One-Size-Fits-All Evaluation. The assessment system used a single, holistic prompt to do evaluation. It would read the whole conversation and make its own determination on the candidate’s qualification with no additional guidance on what the company was looking for.
English Only. At launch, Scout could only conduct interviews in English, which excluded a large portion of our Spanish-speaking workforce.
Operator Safety Net. At this stage, our automated interviews were giving strong directional signals and were a good indicator of intent. The simple assessment meant that AI qualified workers were not always ready to be put on a shift, therefore operators would still call workers to do final vetting and confirmation.
Despite its simplicity, V1 was a breakthrough:
Workers experienced a real phone call with an AI recruiter that didn’t feel robotic.
Operators received structured evaluations instead of raw transcripts, which immediately saved time.
We proved that thousands of interviews could be run in parallel at a fraction of the cost of human-led calls.
When operators called through AI Qualified workers, they had much higher hit rates than cold calling candidates, and had shorter calls since the initial screening asked a lot of the questions a human would need to ask.
Revisions and Improvements
By the end of March, Scout had conducted and ranked over 17,000 interviews. At an average of 5 minutes per conversation, this saved over 1400 operator hours, and gave operators insightful evaluations of areas in which workers qualified or didn’t qualify. While this was immensely helpful, we still had a long way to go to ensure an ideal worker experience.
Moreover, peak season for light industrial staffing, where volume loads can double in a matter of weeks, happens in Q4 - meaning that in order to reliably handle the volume of worker assessments necessary during peak, we needed to upgrade Scout to a level of precision and autonomy such that it would be able to be the sole decision maker on a workers’ qualification – no human vetting required.
Some issues identified:
Language limitations. Currently, interviews could only be conducted in English. This excluded a large swath of principally Spanish speakers who would otherwise be excellent, qualified workers.
Rigid Assessment Taxonomy. Candidates were being assessed on fixed questions associated with the attributes used on the Traba platform. This fixed system didn’t allow enough flexibility to screen for the nuanced requirements that many of our largest customers have.
Context Overload. Given the sheer amount of information that the interview agent was tasked to process, it would occasionally drop questions, fail to dive deep, or otherwise behave unpredictably, degrading the interview experience.
Repetitive Interviews. As a labor platform, Traba can have any number of job openings in any given region that we operate in. Workers often apply for multiple similar roles within a region, and without a system to deduplicate questions, they could be forced to re-answer the same questions from previous interviews conducted only weeks ago.
Weak feedback loops for prompt iterations. To provide our operators reliable and accurate interview assessments, we use a complex prompt to evaluate a worker’s Scout interview transcript and extract specific worker qualifications. Without a strong feedback loop, prompt engineering is guesswork at best.
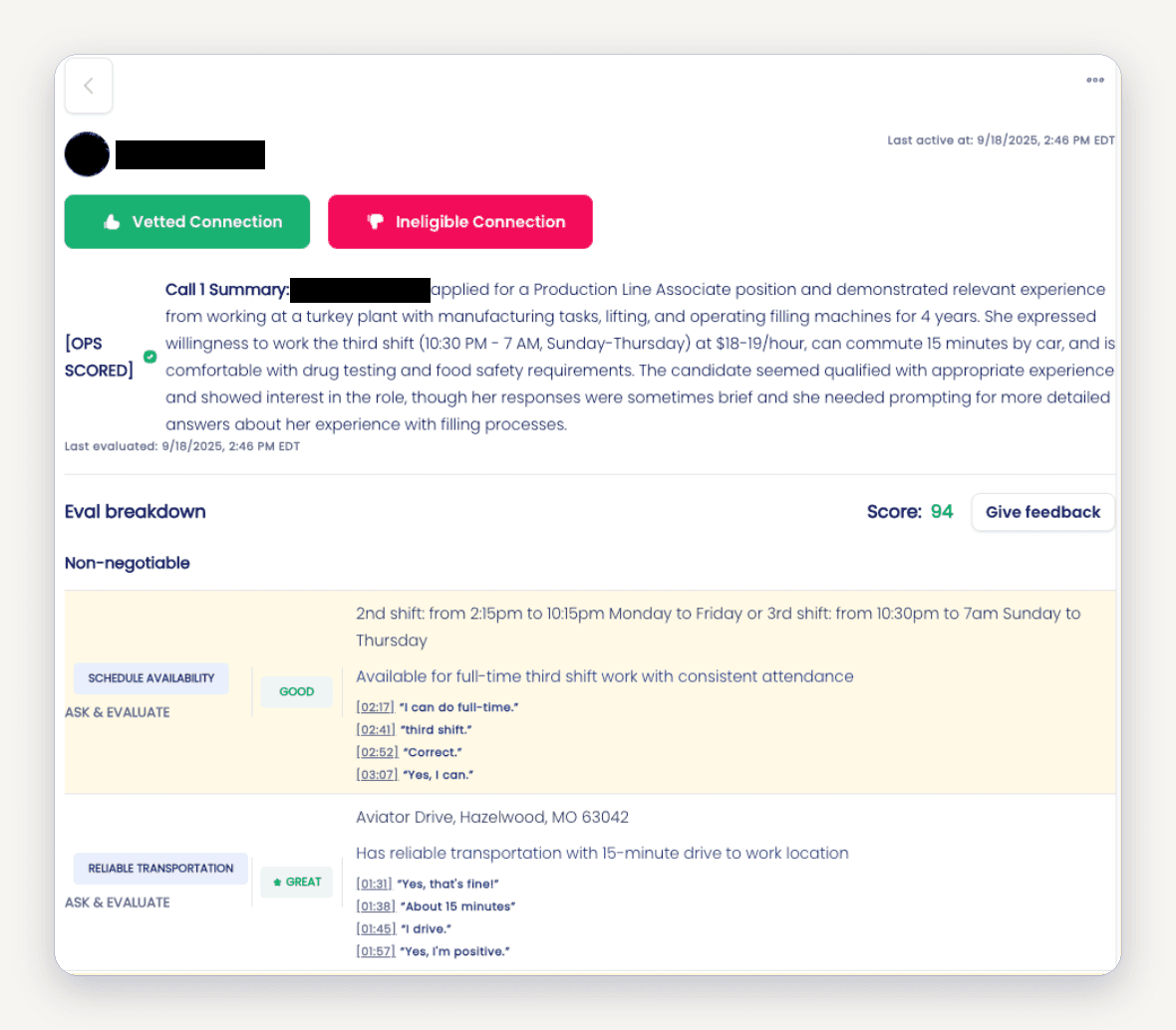
The Solves
Multilingual Agents - We brought this issue up with ElevenLabs, who quickly released language detection & switching. Within a short turnaround, we had a Spanish speaking agent with a natural accent, which we could switch to easily based on the workers’ provided preference. This also forced a slight adjustment to our eval framework, which needed to process transcripts across multiple languages.
Flexible Assessment Framework - Each business has its own internal priorities and processes, and each differs in its labor needs and criteria for employees. Our operators, who spend their days in the field with our customers, have the most context on those customers’ needs. In close partnership with them, we came up with Custom Scout, a flexible assessment framework for operators to train our agents on what constitutes a bad vs good vs great answer for every question.
Multi-agent Support - It’s a natural limitation of agents in 2025 that at a certain threshold of context, they begin to degrade. The solution was to partner with ElevenLabs for a proper system of agent transfer. Instead of having a singular agent hold all of the responsibility for conducting the call, we broke it down into several, each responsible for a different aspect of the vetting call: introducing the job opportunity, vetting the worker for the role, confirming shift logistics, answering worker questions, etc. This resulted in considerably smoother calls, and allowed us to evaluate and assess each vetting agent independently to fine tune the prompting to accomplish the specific goals of each agent.
Deduplicated Interviews - To avoid asking repetitive questions to workers applying to multiple similar jobs, we built a robust pre-processing pipeline to identify and deduplicate semantically similar questions from present and upcoming interviews. This resulted in 10-20% of questions being omitted for workers who had undergone multiple interviews with Traba, saving time and frustration, and giving workers a sense that they were working with an intelligent, dynamic system that truly understood them and their prior history.
Custom datasets and instant feedback loops - To reliably improve our transcript assessment prompts, we built (1) a system for collecting human-annotated ground truths and promoting them into continuously-updating Langfuse datasets and (2) a prompt testing framework to evolve from prompt guessing to prompt engineering.
Off-the-shelf prompt-testing tools couldn’t handle our use case because we weren’t just swapping static prompts – we maintain a single prompt template and inject variables dynamically. Each call can carry different questions and corresponding evaluation logic, so both the inputs and the success criteria vary across calls.
Our testing framework enabled us to reliably test prompt changes in minutes rather than hours; we can concurrently test multiple prompt variations against the same dataset and compare performance across different evaluation criteria with concrete metrics like overall accuracy scores, per-question-type breakdowns, detailed error analyses, and longer-term performance trends.
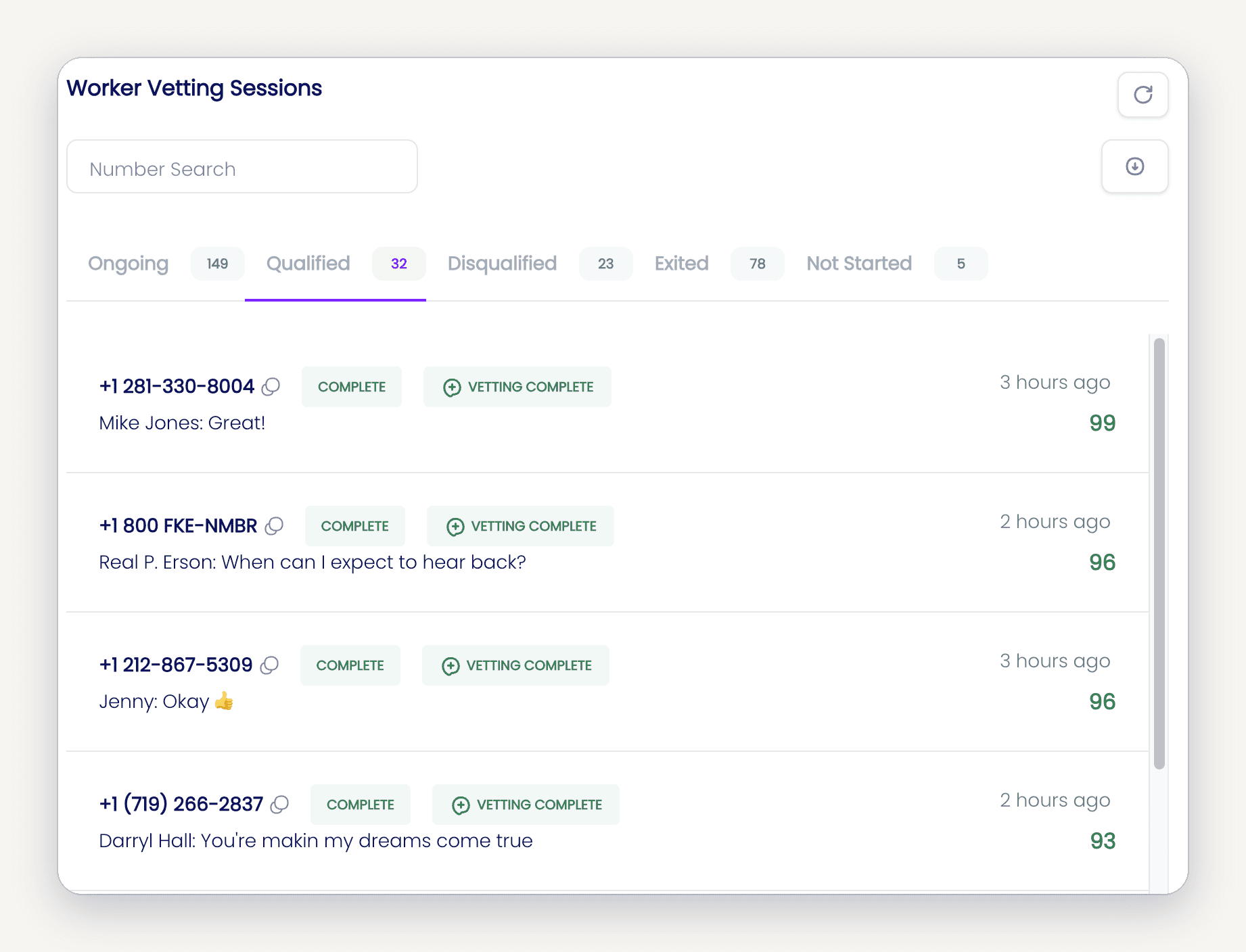
The Stats
To date, we’ve conducted over 250,000 AI led interviews, at a fraction of the cost of human operators, and far beyond the limitations of human parallelism.
Perhaps counterintuitively, AI vetted workers are 15% more likely to successfully complete their shifts when compared to human vetted workers.
A conjecture here is that AI vetted workers undergo a rigorous and tested interview process – perhaps most importantly, a consistent process. Our bank of interview questions and prompts has been empirically refined over the course of thousands of workers and their resulting outcomes and performances. Humans are inherently fallible – well-prompted agents, with the support of human refinement, considerably less so.
Today, over 85% of our vetting is conducted by AI. Within half a year, we should approach 100%, giving workers and businesses a consistent, unbeatable experience in the process.
The Future
Today, we’ve shown that smart, human-in-the-loop trained LLMs for vetting can match or even outmatch humans in accuracy. But that’s not the end - we will surpass humans in depth of inquiry and quality of assessment.
Some angles to approach for the near future:
Realistic Emotion and Sentiment Analysis - by passing the audio in conjunction with the transcript through an LLM, we’ll be able to judge tone of conversation, enthusiasm, or flag areas of concern.
Agentic Interview Generation - currently, optimized interview questions are still curated by our operators, who understand roles, regions and companies to unmatched depth. In the future, this responsibility will be offloaded to a specialized agent as part of an entire orchestrated, agentic process, which will be able to leverage past interview data to fine tune questions based on company intake and feedback.
Agentic Prompt Iteration - Future iterations of our prompt testing framework can leverage agents in the loop – just as human interviewers can study past interviews and improve their process, we expect to build out custom agents in the future to improve on our questions and evaluations against the real world performance of vetted workers over time.
Beyond vetting, many other touch points are required to provide a peerless experience for workers and businesses alike. We’re also working on agents to automate app onboarding, agents for video Q&A sessions, agents to guide workers through shift readiness, agents to automate complex timesheets and invoicing, and much, much more.
To join us on our quest to make the worlds’ supply chains operate at peak efficiency, visit our careers page!
